Fine-tuning is easier than ever. Evaluation isn’t. Are your models grounded? Reliable? Explainable under pressure?
KDCube ExpertFactor trains, evaluates, and benchmarks your AI models against real-world business tasks—with a progressive curriculum approach designed for scalable, explainable results.
We build tailored language models that embody your organization's unique expertise and knowledge base. We train specialized LLMs using your proprietary data, industry terminology, and internal knowledge resources. Unlike generic models that excel on academic benchmarks but fail on specialized tasks, your custom LLMs will speak your organization's language and understand your unique context—delivering more accurate, relevant, and trustworthy responses for your specific applications.
Transform your AI capabilities by fine-tuning LLMs through a comprehensive curriculum-based evaluation framework grounded in your organization's expert knowledge. Reveal both current model capabilities and future learning trajectories, while adapting seamlessly to your architecture—whether you're fine-tuning open-source models, deploying RAG pipelines, or training from scratch.
Build AI systems that integrate regulatory requirements directly into model architecture and behavior. Our framework embeds regulatory guidelines as native constraints within model parameters and decision boundaries. We provide auditable decision paths with documentation that maps directly to GDPR, HIPAA, FCRA, etc. Resulting models naturally operate within your compliance boundaries while delivering high-performance results—reducing risk, streamlining audits, and building stakeholder trust in your AI applications.
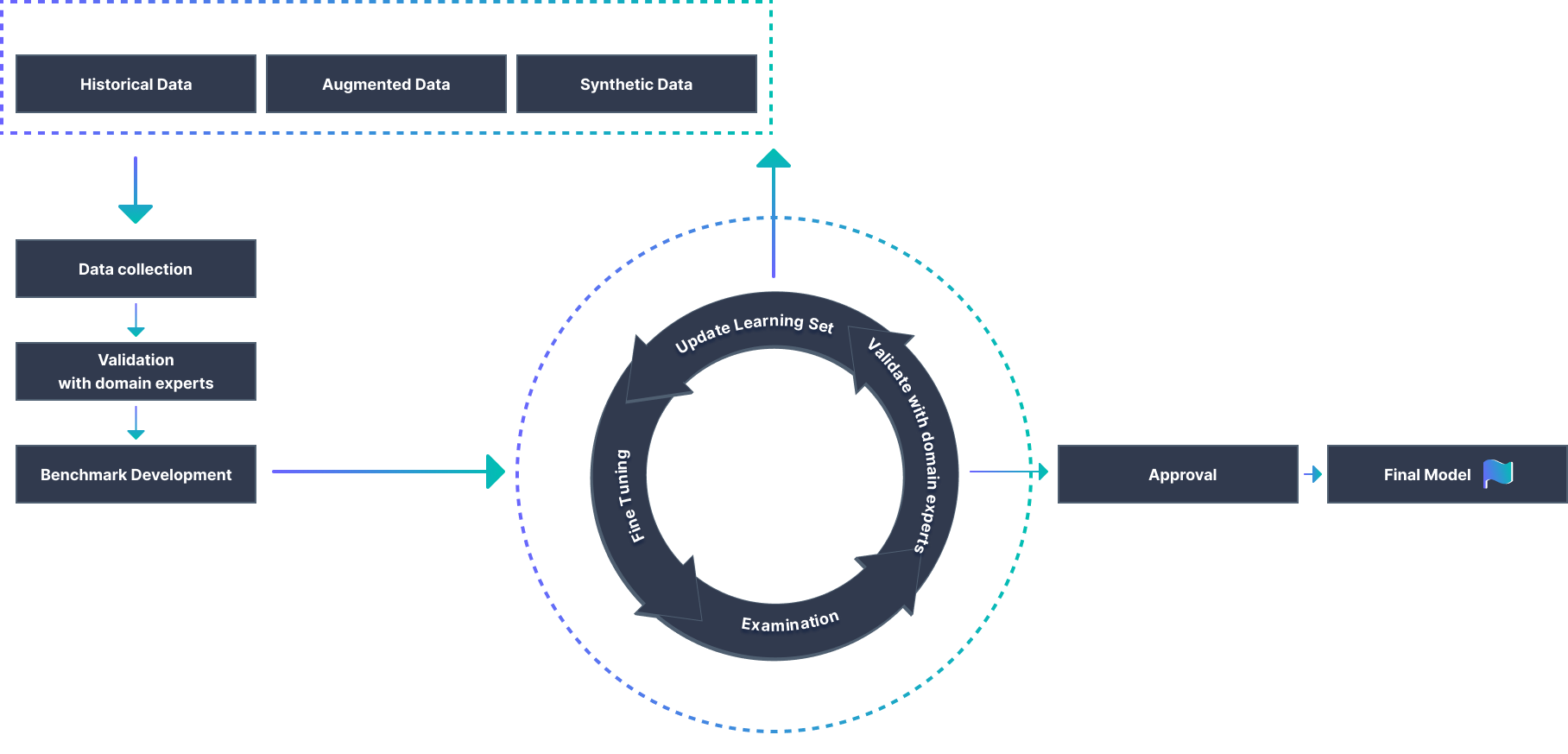
The Knowledge Distillation Workflow: Continuous Improvement at Scale
KDCube’s Expert Factory brings subject-matter expertise directly into the model development loop—boosting performance, reducing inference and retraining costs, and accelerating productivity. All within a controlled, auditable AI environment designed for enterprise-grade reliability.
Design a Curriculum of Tasks Break down your use case into structured evaluation modules—like reasoning steps, compliance checks, or domain-specific problem solving.
Train and Align with Feedback Plug your models into our evaluation engine, track performance at every skill level using AI or human evaluators, and pinpoint where fine-tuning is needed.
Benchmark and Iterate Compare models across releases, architectures, or vendors—using task-focused metrics aligned to your KPIs.
KDCube vs Alternatives
Feature
KDCube
Static Benchmarks
Manual Eval Loops
Task-specific evaluation
✅
❌
✅ (slow)
Curriculum-based skill progression
✅
❌
❌
Plug-and-play for any LLM or RAG
✅
❌
⚠️ (custom only)
Auditability & explainability
✅
⚠️
❌
Scalable across teams & releases
✅
❌
⚠️
Who Benefits from KD Cube?
Designed for AI teams, researchers, and regulated industries that need precise, explainable model evaluation at scale – aligned with compliance frameworks and business objectives.
AI Product Teams
Build smarter assistants and copilots—faster and safer! KDCube helps enterprise AI teams fine-tune, evaluate, and deploy domain-specific models with confidence. Spot reasoning gaps, compare model candidates, and align outputs with AI regulations such as AI Act as well as business-critical standards - before release.
Discover the potential
ML Researchers and Engineers
Accelerate experimentation with structured, explainable evaluation! Whether you're building benchmarks, testing robustness, or fine-tuning open models like LLaMA or Mistral, KDCube gives you the tools to validate progress with repeatable, data-driven insights—at every iteration.
Unlock the benefits!
Regulated Industries and Jurisdictions
Ensure compliance and auditability without slowing innovation! In finance, healthcare, and legal, model transparency isn’t optional. KDCube offers rigorous, policy-aware evaluation frameworks that satisfy internal and external standards—without compromising on speed or performance.
Find out more
"KDCube helped us validate domain-specific copilots with precision. We caught subtle failure modes early—before they reached users."
"Designing evaluation datasets used to take weeks. With KDCube, we stress-test models across scenarios in hours, not days."
"Fine-tuning open models used to feel like guesswork. Now we get targeted feedback after each iteration—no more blind parameter sweeps."
"For us, model validation isn’t optional. KDCube gave us an auditable evaluation trail that satisfied both legal and internal review."
Ready to benchmark your model like a product, not a prototype?
Let us show you how curriculum-based evaluation brings clarity to model development. Request a demo today!